Hadoop的概念随着大(dà)數據時代浪潮的到來,已經變得不那麽陌生(shēng),在實際應用中(zhōng),如何爲Hadoop集群選擇合适的硬件成爲很多人開(kāi)始使用Hadoop的一(yī)個關鍵問題。
在過去(qù),大(dà)數據處理主要是采用标準化的刀片式服務器和存儲區域網絡(SAN)來滿足網格和處理密集型工(gōng)作負載。然而随着數據量和用戶數的大(dà)幅增長,基礎設施的需求已經發生(shēng)變化,硬件廠商(shāng)必須建立創新體(tǐ)系,來滿足大(dà)數據對包括存儲刀片,SAS(串行連接SCSI)開(kāi)關,外(wài)部SATA陣列和更大(dà)容量的機架單元的需求。即尋求一(yī)種新的方法來存儲和處理複雜(zá)的數據,Hadoop正是基于這樣的目的應運而生(shēng)的。Hadoop的數據在集群上均衡分(fēn)布,并通過複制副本來确保數據的可靠性和容錯性。因爲數據和對數據處理的操作都是分(fēn)布在服務器上,處理指令就可以直接地發送到存儲數據的機器。這樣一(yī)個集群的每個服務器器上都需要存儲和處理數據,因此必須對Hadoop集群的每個節點進行配置,以滿足數據存儲和處理要求。
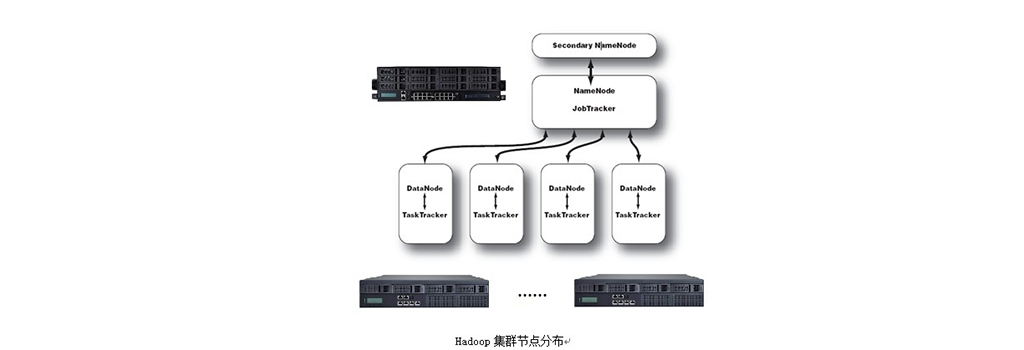
Hadoop框架中(zhōng)最核心的設計是爲海量數據提供存儲的HDFS和對數據進行計算的MapReduce。MapReduce的作業主要包括從磁盤或從網絡讀取數據,即IO密集工(gōng)作,或者是計算數據,即CPU密集工(gōng)作。Hadoop集群的整體(tǐ)性能取決于CPU、内存、網絡以及存儲之間的性能平衡。因此運營團隊在選擇機器配置時要針對不同的工(gōng)作節點選擇合适硬件類型。一(yī)個基本的Hadoop集群中(zhōng)的節點主要有:Namenode負責協調集群中(zhōng)的數據存儲,DataNode存儲被拆分(fēn)的數據塊,Jobtracker協調數據計算任務,最後的節點類型是Secondarynamenode,幫助NameNode收集文件系統運行的狀态信息。
在集群中(zhōng),大(dà)部分(fēn)的機器設備是作爲Datanode和TaskTracker工(gōng)作的。Datanode/TaskTracker的硬件規格可以采用以下(xià)方案:
4個磁盤驅動器(單盤1-2T),支持JBOD
2個4核CPU,至少2-2.5GHz
16-24GB内存
千兆以太網
Namenode提供整個HDFS文件系統的namespace管理,塊管理等所有服務,因此需要更多的RAM,與集群中(zhōng)的數據塊數量相對應,并且需要優化RAM的内存通道帶寬,采用雙通道或三通道以上内存。硬件規格可以采用以下(xià)方案:
8-12個磁盤驅動器(單盤1-2T)
2個4核/8核CPU
16-72GB内存
千兆/萬兆以太網
Secondarynamenode在小(xiǎo)型集群中(zhōng)可以和Namenode共用一(yī)台機器,較大(dà)的群集可以采用與Namenode相同的硬件。考慮到關鍵節點的容錯性,建議客戶購買加固的服務器來運行的Namenodes和Jobtrackers,配有冗餘電(diàn)源和企業級RAID磁盤。最好是有一(yī)個備用機,當 namenode或jobtracker 其中(zhōng)之一(yī)突然發生(shēng)故障時可以替代使用。
目前市場上的硬件平台滿足Datanode/TaskTracker節點配置需求的很多,,據了解深耕網絡安全硬件平台多年的立華科技瞄準了Hadoop的發展前景,适時推出了專門針對NameNode的設備----雙路至強處理器搭載12塊硬盤的FX-3411,将計算與存儲完美融合,四通道内存的最大(dà)容量可達到256GB,完全滿足NameNode對于一(yī)個大(dà)的内存模型和沉重的參考數據緩存組合的需求。
同時在網絡方面,FX-3411支持的2個PCI-E*8的網絡擴展,網絡吞吐達到80Gbps,更是遠遠滿足節點對千兆以太網或萬兆以太網的需求。此外(wài)針對Datanode/TaskTracker等節點的配置需求,立華科技不僅推出了可支持單路至強E3 8核處理器和4塊硬盤的标準品FX-3210,還有可以全面客制化的解決方案,以滿足客戶的不同需求。
Hadoop集群往往需要運行幾十,幾百或上千個節點,構建匹配其工(gōng)作負載的硬件,可以爲一(yī)個運營團隊節省可觀的成本,因此,需要精心的策劃和慎重的選擇。